What is Normalization?
Database normalization is a data design and organization process applied to data structures based on rules that help building relational databases. In relational database design, the process of organizing data to minimize redundancy is called normalization. Normalization usually involves dividing a database into two or more tables and defining relationships between the tables. The objective is to isolate data so that additions, deletions, and modifications of a field can be made in just one table and then propagated through the rest of the database via the defined relationships.
Detecting Low Disk Space on Server
A very common question I often receive is how to detect if the disk space is running low on SQL Server.
EXEC MASTER..xp_fixeddrivesGO
Recursive CTE
A CTE that references itself is called as recursive CTE. Recursive CTE's can be of great help when displaying hierarchical data.
WITH NumbersCTE AS
(
SELECT 1 AS Number
UNION ALL
SELECT Number + 1 FROM NumbersCTE
WHERE Number <10
)
SELECT * FROM NumbersCTE
WITH NumbersCTE AS
(
SELECT 1 AS Number
UNION ALL
SELECT Number + 1 FROM NumbersCTE
WHERE Number <10
)
SELECT * FROM NumbersCTE
Difference between DATEPART and DATENAME
DatePart(DatePart, Date) - Returns an integer representing the specified DatePart. This function is simialar to DateName(). DateName() returns nvarchar, where as DatePart() returns an integer.
Example:
Select DATEPART(weekday, '2012-08-30 19:45:31.793') -- returns 5
Select DATENAME(weekday, '2012-08-30 19:45:31.793') -- returns Thursday
How to continue with whats app in blackberry/andriod after june 30?
Hello dear reader!
This is my first post in reference to a fix WhatsApp on BlackBerry Z10. Today I do it!
All this story was an adventure 'cause recently I bought an BlackBerry Z10 like new! Although, I new the problem with compatibility and the last chance until June 30th, 2017.
Well I decided looking for one solution about this problem and the solution it is as follow:
I'm trying install WhatsApp via "1 Mobile Market" app. Please follow the instructions:
1.- Look for "1 Mobile Market" APK in Google. Here is a link: http://market.1mobile.com/
2.- Install those APK that you downloaded in step 1.
3.- Open the 1 Mobile Market.
4.- Look for WhatsApp in this Market.
5.- Install WhatsApp
6.- Enjoy it!
This is my first post in reference to a fix WhatsApp on BlackBerry Z10. Today I do it!
All this story was an adventure 'cause recently I bought an BlackBerry Z10 like new! Although, I new the problem with compatibility and the last chance until June 30th, 2017.
Well I decided looking for one solution about this problem and the solution it is as follow:
I'm trying install WhatsApp via "1 Mobile Market" app. Please follow the instructions:
1.- Look for "1 Mobile Market" APK in Google. Here is a link: http://market.1mobile.com/
2.- Install those APK that you downloaded in step 1.
3.- Open the 1 Mobile Market.
4.- Look for WhatsApp in this Market.
5.- Install WhatsApp
6.- Enjoy it!
PIVOT and UNPIVOT
PIVOT is one of the New relational operator introduced in Sql Server 2005. It provides an easy mechanism in Sql Server to transform rows into columns.




Example:
CREATE TABLE #CourseSales
(Course VARCHAR(50),Year INT,Earning MONEY)
GO
--Populate Sample records
INSERT INTO #CourseSales VALUES('.NET',2012,10000)
INSERT INTO #CourseSales VALUES('Java',2012,20000)
INSERT INTO #CourseSales VALUES('.NET',2012,5000)
INSERT INTO #CourseSales VALUES('.NET',2013,48000)
INSERT INTO #CourseSales VALUES('Java',2013,30000)
GO
select * from #CourseSales
By Using PIVOT Operator
select * from #CourseSales
pivot(sum(earning) for course in([.net],[Java])) as PIVOTTABLE

SELECT *
FROM #CourseSales
PIVOT(SUM(Earning)
FOR Year IN ([2012],[2013])) AS PVTTable
By Using UNPIVOT
UNPIVOT is the reversal of the PIVOT operation. It basically provides a mechanism for transforming columns into rows.
From the above image it is clear that UNPIVOT is the reversal of the PIVOT operation. But it is not the exact reversal of PIVOT operation as PIVOT operation generates the aggregated result, so UNPIVOT will not be able to split the aggregated result back to the original rows as they were present prior to the PIVOT operation.
As depicted in the above image there were 5 rows in the #CourseSales Table Prior to PIVOT, but a PIVOT and it’s reversal UNPIVOT resulted in 4 rows only. The reason for this is for .NET Course in Year 2012 there were two records one with earning 10K and another with earning 5K, the PIVOT and it’s reversal UNPIVOT result last lost this split information and instead of two rows it has generated one row for the .NET course in Year 2012 with Earning as sum of 10K and 5K i.e. 15K.
We can use the below script to simulate the PIVOT and UNPIVOT operation as depicted in the above image on the #CourseSales Temporary Table created in the beginning PIVOT section of this article.
--PIVOT the #CourseSales table data on the Course column SELECT *INTO #CourseSalesPivotResultFROM #CourseSalesPIVOT(SUM(Earning) FOR Course IN ([.NET], Java)) AS PVTTableGO--UNPIVOT the #CourseSalesPivotResult table data --on the Course column SELECT Course, Year, EarningFROM #CourseSalesPivotResultUNPIVOT(Earning FOR Course IN ([.NET], Java)) AS UNPVTTableSql query to select all names that start with a given letter without like operator
We will use the following Students table for this example

SQL Script to create the Students table
Interview question : Write a query to select all student rows whose Name starts with letter 'M' without using the LIKE operator
The output should be as shown below
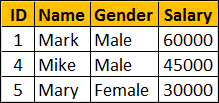
If the interviewer has not mentioned not to use LIKE operator, we would have written the query using the LIKE operator as shown below.
We can use any one of the following 3 SQL Server functions, to achieve exactly the same thing
CHARINDEX
LEFT
SUBSTRING
The following 3 queries retrieve all student rows whose Name starts with letter 'M'. Notice none of the queries are using the LIKE operator.
SQL Script to create the Students table
Create table Students
(
ID int primary key identity,
Name nvarchar(50),
Gender nvarchar(50),
Salary int
)
Go
Insert into Students values ('Mark', 'Male', 60000)
Insert into Students values ('Steve', 'Male', 45000)
Insert into Students values ('James', 'Male', 70000)
Insert into Students values ('Mike', 'Male', 45000)
Insert into Students values ('Mary', 'Female', 30000)
Insert into Students values ('Valarie', 'Female', 35000)
Insert into Students values ('John', 'Male', 80000)
Go
Interview question : Write a query to select all student rows whose Name starts with letter 'M' without using the LIKE operator
The output should be as shown below
If the interviewer has not mentioned not to use LIKE operator, we would have written the query using the LIKE operator as shown below.
SELECT * FROM Students WHERE Name LIKE 'M%'
We can use any one of the following 3 SQL Server functions, to achieve exactly the same thing
CHARINDEX
LEFT
SUBSTRING
The following 3 queries retrieve all student rows whose Name starts with letter 'M'. Notice none of the queries are using the LIKE operator.
SELECT * FROM Students WHERE CHARINDEX('M',Name) = 1
SELECT * FROM Students WHERE LEFT(Name, 1) = 'M'
SELECT * FROM Students WHERE SUBSTRING(Name, 1, 1) = 'M'
Ways to remove duplicate values
There are different methods for deleting duplicate (de-duplication) records from a table, each of them has its own pros and cons. I am going to discuss these methods, prerequisite of each of these methods along with its pros and cons.
In this approach we pull distinct records from the target table into a temporary table, then truncate the target table and finally insert the records from the temporary table back to the target table
Script:
- Using correlated subquery
- Using temporary table
- Creating new table with distinct records and renaming it..
- Using Common Table Expression (CTE)
- Using Fuzzy Group Transformation in SSIS
- Using MERGE Statement
In this approach we pull distinct records from the target table into a temporary table, then truncate the target table and finally insert the records from the temporary table back to the target table
| CREATE TABLE Employee ( [FirstName] Varchar(100), [LastName] Varchar(100), [Address] Varchar(100), ) GO INSERT INTO Employee([FirstName], [LastName], [Address]) VALUES ('Linda', 'Mitchel', 'America') INSERT INTO Employee([FirstName], [LastName], [Address]) VALUES ('Linda', 'Mitchel', 'America') INSERT INTO Employee([FirstName], [LastName], [Address]) VALUES ('John', 'Albert', 'Australia') INSERT INTO Employee([FirstName], [LastName], [Address]) VALUES ('John', 'Albert', 'Australia') INSERT INTO Employee([FirstName], [LastName], [Address]) VALUES ('John', 'Albert', 'Australia') INSERT INTO Employee([FirstName], [LastName], [Address]) VALUES ('Arshad', 'Ali', 'India') INSERT INTO Employee([FirstName], [LastName], [Address]) VALUES ('Arshad', 'Ali', 'India') INSERT INTO Employee([FirstName], [LastName], [Address]) VALUES ('Arshad', 'Ali', 'India') INSERT INTO Employee([FirstName], [LastName], [Address]) VALUES ('Arshad', 'Ali', 'India') GO SELECT * FROM Employee GO |
Script:
BEGIN TRAN
-- Pull distinct records in the temporary table
SELECT DISTINCT * INTO #Employee FROM Employee --Truncate the target table
TRUNCATE TABLE Employee --Insert the distinct records from temporary table
--back to target table
INSERT INTO Employee SELECT * FROM #Employee --Drop the temporary table
IF OBJECT_ID('tempdb..#Employee') IS NOT NULL
DROP TABLE #Employee
COMMIT TRAN
GO
SELECT * FROM Employee
GO
-- Pull distinct records in the temporary table
SELECT DISTINCT * INTO #Employee FROM Employee --Truncate the target table
TRUNCATE TABLE Employee --Insert the distinct records from temporary table
--back to target table
INSERT INTO Employee SELECT * FROM #Employee --Drop the temporary table
IF OBJECT_ID('tempdb..#Employee') IS NOT NULL
DROP TABLE #Employee
COMMIT TRAN
GO
SELECT * FROM Employee
GO
Creating new table with distinct records and renaming it
In this approach we create a new table with all distinct records, drop the existing target table and rename the newly created table with the original target table name. Please note, with this approach the meta-data about the target table will change for example object id, object creation date etc. so if you have any dependencies on these you have to take them into consideration.
Three things you need to aware of when you are using this approach.
- First you need to make sure you have enough space in your database in the default filgroup (if you want your new table to be on some other file group than the default filegroup then you need to create a table first and then use INSERT INTO....SELECT * FROM) to hold all the distinct records especially if it is very large result-set.
- Second you need to make sure you perform this operation in a transaction, at least the DROP and RENAME part so that you are not left with an another problem if it fails in between for any reason.
- Third you need to have required permissions for object creation/drop.
Script #4 - New table with distinct only
|
| BEGIN TRAN -- Pull distinct records in a new table SELECT DISTINCT * INTO EmployeeNew FROM Employee --Drop the old target table DROP TABLE Employee --rename the new table EXEC sp_rename 'EmployeeNew', 'Employee' COMMIT TRAN GO SELECT * FROM Employee GO |
Subscribe to:
Comments (Atom)